雜談
感謝obarisk邦友在Day11的回覆,也感謝提供實作自訂向量化函式,我後來也有在Stack Overflow看到類似的討論How to define a vectorized function in R,而在cheatsheet會提到那些韓函式屬於vectorized functions,其定義是以向量作為輸入,並輸出與輸入相同長度的向量,應該也如obarisk在Day9提到的dplyr多有向量化。總之,感謝obarisk邦友的回饋。
正文
今天要來紀錄搭配summarize()的彙總函式(Summary Functions),彙總函式以向量輸出會得到單一值。
計算每個汽缸數 (cyl) 分組中的汽車數量
mtcars |>
group_by(cyl) |>
summarize(
count = n()
)

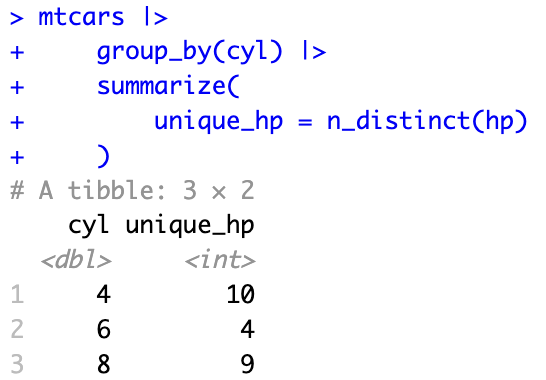
計算每個汽缸數 (cyl) 分組中的唯一馬力 (hp) 數量
mtcars |>
group_by(cyl) |>
summarize(
unique_hp = n_distinct(hp)
)
創建新的範例資料集(有NA的資料集)
# 建立包含 NA 值的範例資料集
df <- data.frame(
group = c("A", "A", "B", "B", "C", "C"),
value = c(10, NA, 20, 30, NA, 40)
)
# 查看範例資料集
print(df)

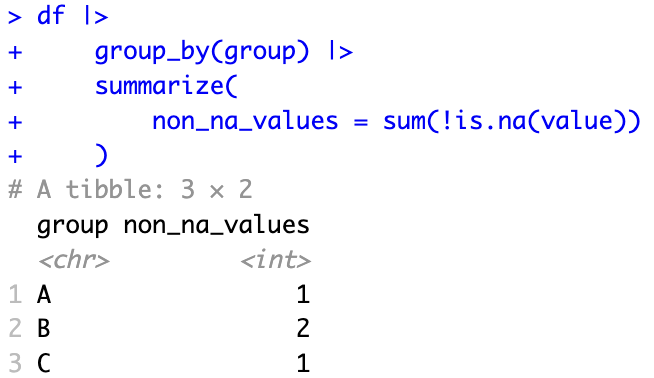
計算每個分組(group)中非缺失值(value)的數量。
df |>
group_by(group) |>
summarize(
non_na_values = sum(!is.na(value))
)
計算每個分組(group)中 value 的平均值,忽略 NA 值。
df |>
group_by(group) |>
summarize(
avg_value = mean(value, na.rm = TRUE) # 忽略NA值計算平均
)

計算每個分組(group)中 value 的中位數,忽略 NA 值。
df |>
group_by(group) |>
summarize(
median_value = median(value, na.rm = TRUE) # 忽略NA值計算中位數
)

參考資料:

